

.png)


Robustness index is a simple metric that allows us to quantify the annotators’ contribution from an additional perspective. This is a general statistic for robustness that, in our case, takes into account the number of positive contributions versus negative contributions of the annotation step. A positive contribution occurs when the annotator is correct while the model is wrong, meaning the annotator ‘helps’ the model. Whereas a negative contribution occurs when the model is correct and the annotator is wrong, meaning the annotator ‘hurts’ the model’s performance rather than improving it. All other cases, when both the model and the annotator are correct or both are wrong, are ignored.
Examining the amount of negative and positive contributions can help us get the complete picture of each annotator’s performance and evaluate each annotator’s contribution in detail. The Robustness Index itself is calculated by:
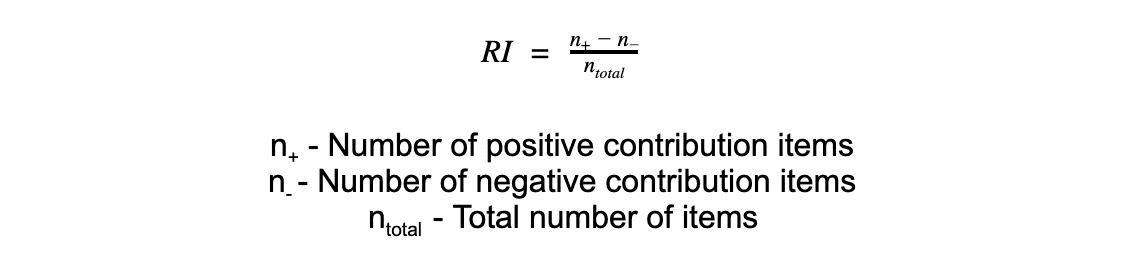
RI values range between -1 and 1, where -1 means the annotation has a completely negative contribution to the system, 0 means there is no contribution, and 1 means a completely positive contribution. Notice RI of 0 can be received from either the same exact predictions, or by having n+ equal to n-. The desired robustness scores for each of the annotators is of course a positive one, and the higher the score the better. As each annotators’ contribution is calculated by correcting inaccurate model predictions, the score remains limited by the number of model mistakes. To simplify the calculation, labelling only items where the predictions of the model and the annotator differ is an option, which makes it easier to calculate compared to accuracy.
Using this metric, we’ve been able to evaluate and compare our annotators’ contributions — which has played a key role in deciding which data to display to our users. As shown in Table 1, we can be sure that 7 out of 10 of the annotators provide quality annotations due to their positive RI. For the 3 annotators with a negative RI, we simply ignore their annotations in the product dashboard and exclude their annotations from model training datasets.
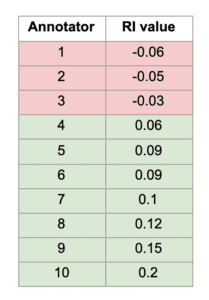 Table 1: Robustness Index values of different annotators
Table 1: Robustness Index values of different annotators
Model confidence scores provide information about the reliability of each of the model’s predictions. This is usually a decimal number between 0 and 1, which can be interpreted as a percentage of confidence – or how confident the model is about its prediction.
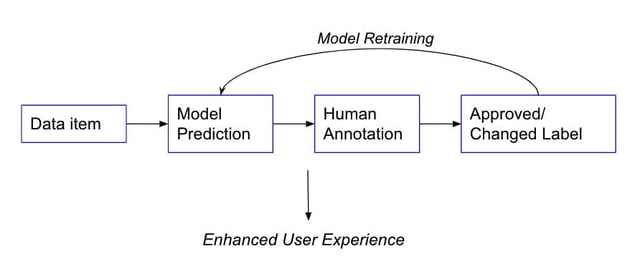
An additional approach to assess annotation quality is examining the accuracy of the Human-in-the-Loop system described in Diagram 1 above with regards to the model confidence scores. By measuring the accuracy received by letting the annotators annotate only up to a certain confidence score, an optimal confidence score threshold can be found. The accuracy should be calculated by combining the two parts – below and above the threshold. The total accuracy is reached by merging the annotator accuracy below the threshold and the model accuracy above the threshold.
In the example shown in Graph 1, the accuracy reaches a plateau and does not increase from a certain confidence score equal to 0.6, meaning the annotation step has no contribution for high-confidence items. This score can be set as a threshold, so that model predictions with a higher score than this threshold will not be manually annotated. Instead, the model prediction itself will be used. While maintaining the same accuracy, we reduce the efforts of annotating items with confidence scores higher than 0.6.
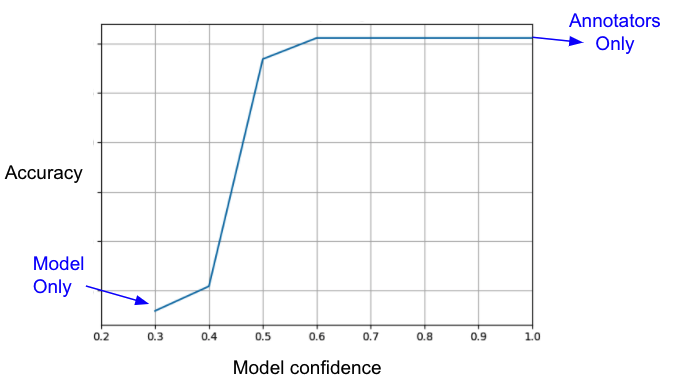
Graph 1: Accuracy for different model confidences; accuracy reaches a plateau from a certain score
The above example shows us that setting a threshold based on our data can save us time and prevent unnecessary annotation efforts. In some cases, it can also result in a higher total accuracy of the combined system, as can be seen in Graph 2. The latter will occur in cases where the model’s predictions for the high confidence items are more accurate than the annotators’ results for this group. This is a great example of the impact we can make by creating data driven results based on our own data.
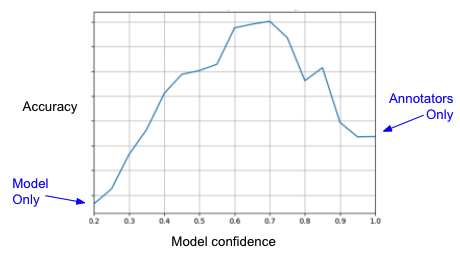
Graph 2: Accuracy for different model confidences; accuracy reaching its peak for a certain mid-score
In the example shown in Graph 2, the accuracy reaches its peak for a certain confidence, and decreases when annotators tag high confidence items. In this case, the annotation process has a negative contribution if it includes high-confidence items! This means the annotators hurt the performance of the system, but it is visible to us only if we check the accuracy as a function of the model confidence scores.
At a first glance, it seems the annotators’ total contribution is positive, as the annotators’ accuracy is higher than the model accuracy alone. But practically, a negative effect is present for high confidence items, and we can use a threshold to get higher accuracy as well as reduce annotation efforts. This way, we benefit in two major ways: we get a better user experience and we save time, increasing efficiency. As can be seen in the graph, if we use a threshold of 0.7 we get the highest accuracy possible for this system, and in addition to that, we save the costs of annotating items with confidence higher than 0.7.
By further investigating annotation quality using model confidence scores, we can adjust the system to enhance our models’ performance and better utilize annotation efforts.
Ready to get started?
Reach out to our team to schedule a demo.
